

近日,由Association for ComputingMachinery主办的ACM MM 2023(ACM International Conference onMultimedia, CCF A类会议)公布论文的收录结果,维多利亚国际娱乐官网2篇论文被录用,第一作者分别为多媒体认知计算实验室2022级博士生余鹏航与2022级博士生袁博闻。研究内容涵盖多媒体推荐、低资源视觉问答等多个研究方向,展示了维多利亚国际娱乐官网多媒体认知计算实验室在人工智能与多媒体领域的技术能力和学术成果。录用论文“Multi-View Graph Convolutional Network forMultimedia Recommendation”提出了一种针对多媒体推荐的多视图图卷积网络,使用用户行为信息作为引导,解决了商品模态噪声污染问题并增强了模型对用户偏好的建模能力;录用论文“Self-PT: Adaptive Self-Prompt Tuning forLow-Resource Visual Question Answering” 提出了针对视觉问答任务的自适应提示学习方法,使用问题-图像对作为条件生成动态的实例级提示,解决了静态提示和可见答案间的过拟合问题。
ACM MM是计算机图形学与多媒体领域的顶级国际会议,也是中国计算机学会推荐的该领域唯一的A类国际学术会议。本届ACM MM有效投稿量达3072篇,接收论文902篇,接收率约为29.3%。
论文介绍
1.论文题目:Multi-View Graph Convolutional Network for MultimediaRecommendation
作者:余鹏航,谭智一,卢官明,鲍秉坤
通讯作者:鲍秉坤
论文概述:
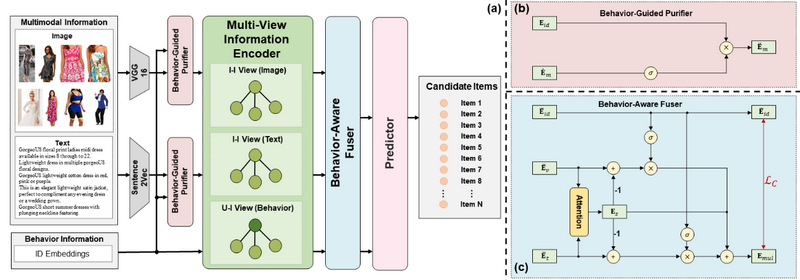
近年来,多媒体推荐饱受学术界和工业界关注,其基于用户行为信息和物品多模态信息来建模用户偏好,从而为用户推荐感兴趣的物品。目前,尽管基于图卷积神经网络(GCN)的多媒体推荐方法已经取得了不错的推荐效果,但他们存在着两个缺陷:(1)现有方法忽视了物品多模态信息中存在着与用户偏好无关的噪声信息。同时,现有基于GCN的方法通常在单一视图(例如用户-物品视图)中建模用户偏好,这导致物品多模态特征和用户行为特征高度耦合,从而使得物品多模态信息中的噪声将污染用户行为特征,这导致了用户偏好区分度的降低;(2)平等的对待物品不同模态下的信息不足以充分建模用户偏好。由于用户在购买物品时对物品不同模态信息关注度不同,因此如果平等的对待物品不同模态下的信息将导致次优的用户偏好建模。
为了解决上述问题,该论文提出了一种针对多媒体推荐的多视图图卷积网络(MGCN)。具体来说,为了避免模态噪声污染,该论文首先利用用户行为信息对物品的模态特征进行了净化。然后,在不同视图下对行为特征和模态特征进行特征聚合,从而捕获用户对于不同模态的偏好特征。进一步的,该论文设计了一个行为感知的融合器,其根据用户对不同模态的关注度,自适应的融合商品不同模态特征,从而全面地建模用户偏好。此外,该论文为融合器的训练设计了一个自监督辅助任务。该任务旨在最大化模态特征与行为特征之间的互信息,以鼓励模型进一步捕捉行为信息与模态信息之间的相似信息与互补信息。在三个公共数据集上的大量实验表明,该论文的方法优于现有的多模态推荐方法。
项目地址:https://github.com/demonph10/MGCN
2.论文题目:Self-PT: Adaptive Self-Prompt Tuning forLow-Resource Visual Question Answering
作者:袁博闻,游思思,鲍秉坤
通讯作者:鲍秉坤
论文概述:
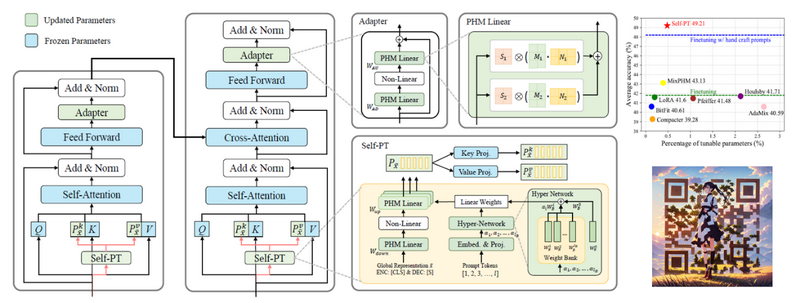
视觉问答任务要求计算机能够根据图像和文本问题给出相应的文本答案。该任务能够衡量一个模型的跨模态理解能力,因而在互联网时代有着重要的研究价值和意义。现如今,预训练和微调大型跨模态模型在视觉问答任务取得了不错的效果,但是在低资源场景下的视觉问答任务中,完全微调方法大量消耗计算资源,且容易过拟合可见样本。以往的提示学习方法虽然减少了微调模型的参数量,但是它们无法在提示编码期间进行上下文感知,导致:1)对未见问题类别的泛化能力差;2)参数效率低,增加参数量只能获得有限的性能提升。
为增强模型对未见问题的泛化能力,该论文提出了自适应提示学习方法,使用问题-图像对作为条件生成动态的实例级提示,解决了静态提示和可见答案间的过拟合问题。为了进一步减小参数量,该论文提出了超网络结构与参数低秩分解方法。超网络结构可以解耦自适应提示学习模块参数量与提示长度的相关性,使得固定参数量下可以生成任意长度的提示。参数低秩分解方法可以在一个低秩空间中重新表示自适应提示学习模块的参数,进一步降低模块参数量。在VQA,GQA,OK-VQA三个视觉问答数据集上,不同可见样本数量的设置下视觉问答正确率均优于完全微调以及现有的参数高效微调方法。
项目地址:https://github.com/NJUPT-MCC/Self-PT
(撰稿:聂凡 编辑:吕瑞兰 审核:徐雷)