

2020年7月1日,第六届国际权威声学场景和事件检测及分类竞赛 (Detection andClassification of Acoustic Scenes and Events,DCASE2020) 结果揭晓,北京邮电大学和南京邮电大学联合组成的代表队荣获自动音频标注(Automated Audio Caption,Task 6)任务竞赛全球第二名的好成绩。
此次参赛队伍由北京邮电大学李圣辰,安徽大学年福东,南京邮电大学邵曦三位老师共同指导,参赛队员为北邮的吴雨松同学和陈堃同学,南邮的王子岳同学和张暄同学。这是他们首次参加自动音频标注(Task 6)任务竞赛,也是南北二邮首次携手参加声学场景和事件检测及分类竞赛。
DCASE 挑战赛是由伦敦玛丽女王大学(Queen Mary University ofLondon)在2013年首次发起的声学场景识别挑战,后续由坦佩雷理工大学(Tamper University of Technology)持续发起,近些年引起了国内外众多尖端声学研究界的广泛关注。本次比赛吸引了亚马逊,三星电子,IBM,日本电信电话NTT集团等知名企业和清华大学,霍普金斯大学,南洋理工大学等国内外知名高校的众多队伍参加。
本次T6组的自动音频标注任务,需要使用自由文本对一般音频内容进行描述。这是一个多模态翻译任务,系统接收一个音频信号作为输入并输出该信号的文本描述,它可以建模概念(如,低沉的声音),物体(如一辆大汽车的声音)和环境(如人们在小而空的房间里谈话的声音)的物理特性,以及高层次的知识(如一个时钟响了三次)。
图一:自动音频标注系统的过程图示
此次比赛,该组提出了一个序列到序列模型,该模型由CNN作为编码器,Transformer作为解码器。在该模型中,首先对编码器和词嵌入进行预训练,在训练过程中应用正则化和数据增强技术,并在训练后进行微调。相比传统基于LSTM的基准方法,可以更好的生成对于音频的描述。在比赛规则禁止使用外部数据与预训练的约束下,该组提出的方案解决了由于数据有限,直接从头端到端训练的模型对于声学事件和语言建模较差的情况,从而可以更好地进行声音事件和语言的建模。
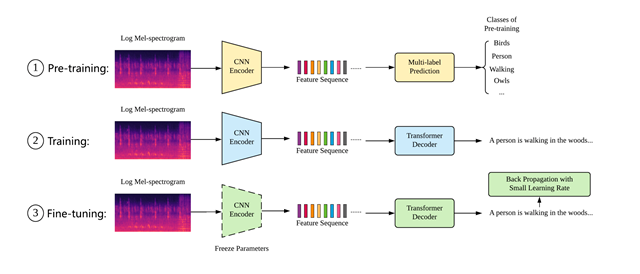
图二:模型概述图
如图所示,编码器提取输入对数梅尔谱图的特征向量序列,解码器在处理特征序列时生成每个单词。首先对编码器进行多标签预测的预训练的任务,在训练后进行微调。图中所示的CNN编码器在训练前、训练期间保持相同的架构和微调。最终,该模型在音频标注性能方面在参赛的11支队伍中脱颖而出,获得本次挑战的第二名。