

我校“通信与网络技术”国家工程研究中心周全副教授课题组与美国天普大学Longin Jan Latecki教授合作,在图像实时语义分割领域取得新突破。该课题组在深度学习框架下提出了一种轻量级的实时图像语义分割网络:LEDNet(Light Encoder-DecoderNetwork)。该网络整体架构如图1所示。LEDNet在资源受限条件下实现了卷积神经网络前向推理速度和分割精度之间的平衡。在单个GTX 1080Ti GPU中该网络能够以超过71 FPS的速度运行,且在公测数据集上表现出具有竞争力的分割精度。该成果近期发表在2019年第26届IEEE国际图像处理大会 (IEEE InternationalConference on Image Processing, ICIP 2019)上,并受邀作大会(分组)口头报告。
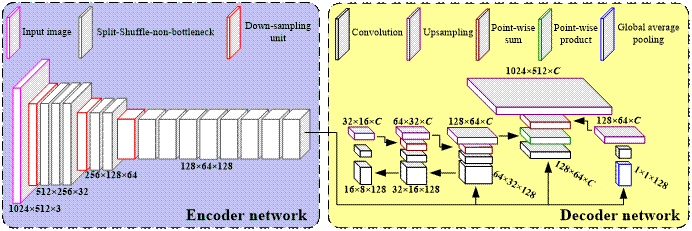
图1 LEDNet网络详细架构
图像语义分割是计算机视觉领域的一项基本任务,旨在为一张图像之中的每个像素分配语义标签,可广泛应用于视频监控、增强现实、自动驾驶、医学图像诊断等领域,因而得到学术界和工业界的广泛关注。自第一个全卷积网络(FCN)提出以来,深度卷积神经网络在语义分割精度方面取得了巨大进展。当前语义分割领域的研究主要集中在两个方向:一是通过增加网络层级、增大网络复杂度提升网络分割精度;二是通过降低网络复杂度、减少参数量提升网络运行效率。现有的语义分割网络如UNet,PSPNet,DeepLab等虽然取得较高的分割精度,但受限于庞大的参数量,其运行速度远无法满足实时性的要求。而在实际落地时,越来越多的应用场景需要精确且高效的分割技术。最近,语义分割模型的加速取得一定进展,如减少网络通道数量、压缩预训练模型、设计小尺度卷积网络等方法,但这些方法面临模型分割精度较低等问题。
针对该缺点,我校周全副教授课题组联合美国天普大学Longin Jan Latecki教授,提出用于实时图像语义分割的轻量级网络LEDNet。该网络通过设计非对称编解码网络架构,减少模型参数,进而加速网络前向推理过程;其次改进传统残差块中的卷积结构,通过引入增强信息交互的机制以提升整个网络的表达能力;最后在解码端采用注意力机制设计APN架构,自适应地集成特征之间的相互关联性。该方法在未采用任何后处理手段(如CRF)的情况下,显著加速语义分割推理速度的同时且能保持较高的分割精度。该方法也为计算机视觉中的其它任务,如目标检测、深度预测、表情识别等提供新的研究思路与应用方法。目前该方法已被成功的用于人物肖像分割领域。
该项工作的第一作者是我校维多利亚老品牌76696vic硕士研究生王雨,“通信与网络技术”国家工程研究中心的周全副教授是该工作的通讯作者。该项工作受到国家自然科学基金、江苏省自然科学基金、美国国家自然科学基金以及华为HIRP基金等项目的支持。